Misc-2023CISCN东北赛区线下赛-剪不断理还乱-writeup
线下没做出来这道题 感谢赛后App1e_Tree师傅的帮助
题目是一张png图片

拖到tweakpng查看
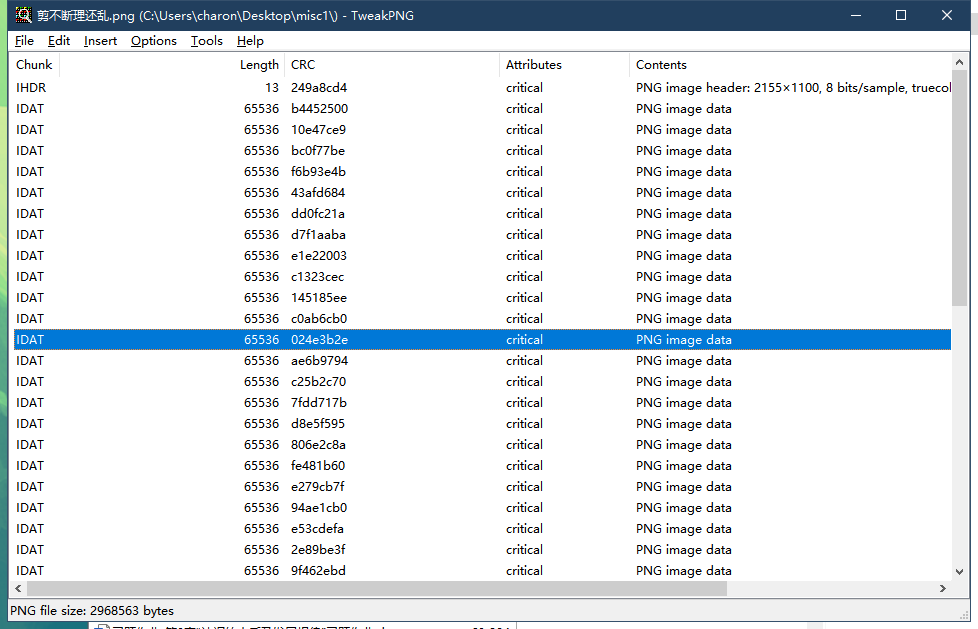
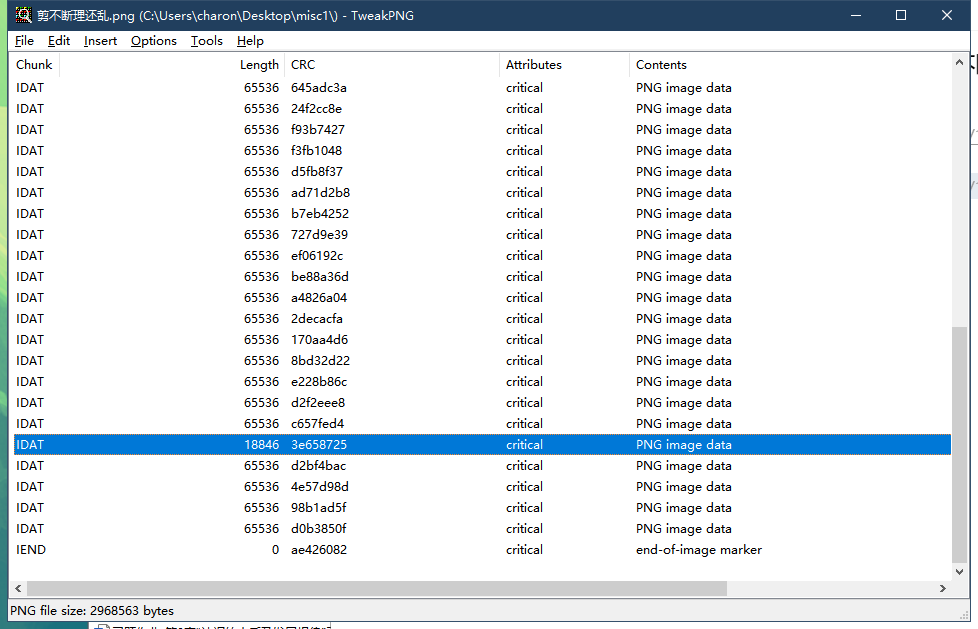
中间有一块IDAT大小不对 按照PNG的格式要求应该是 最小的IDAT在最下面 结合题目
判断是IDAT顺序不对
尝试对IDAT的顺序进行爆破
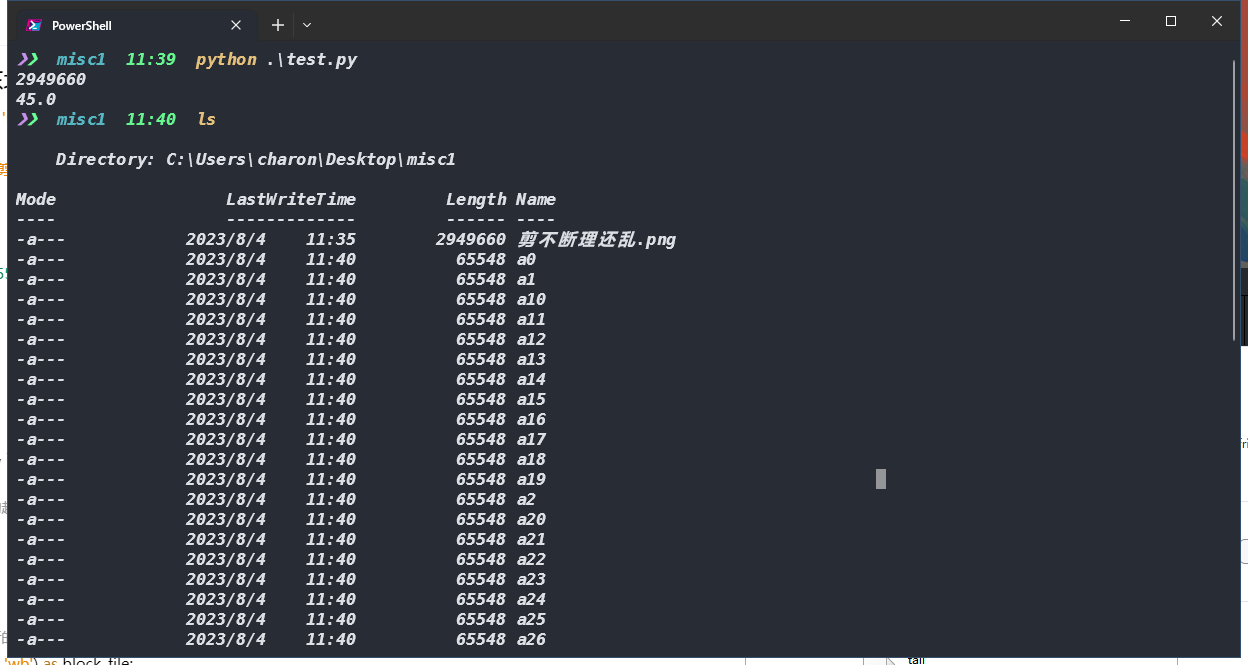
首先我们对图片进行拆分 先
把图片的文件头拆分出来命名为head
文件尾拆分出来命名为tail
最小的那块长度为18846的IDAT拆分出来命名为a45

然后把剩余的IDAT块等分
脚本
import os
# 打开要分割的文件
with open('剪不断理还乱.png', 'rb') as f:
# 获取文件的长度
file_size = os.path.getsize('剪不断理还乱.png')
print(file_size)
print(file_size/65548)
# 计算需要分割成多少块
num_blocks = file_size // 65548
# 分割文件
for i in range(num_blocks):
# 计算当前块的起始位置
start = i * 65548
# 计算当前块的结束位置
end = min(start + 65548, file_size)
# 定位文件指针到当前块的起始位置
f.seek(start)
# 读取当前块的数据
data = f.read(end - start)
# 将当前块的数据写入到新的文件中
with open('a{}'.format(i), 'wb') as block_file:
block_file.write(data)
然后写脚本爆破
# 指定要拼接的文件列表
file_names = ['head',
'x',
'tail']
# 创建一个新的文件来保存拼接后的数据
for i in range(0, 46):
with open('.//output//'+str(i)+'.png', 'wb') as f:
file_names[-2] = "a"+str(i)
# 遍历所有文件
for file_name in file_names:
# 打开当前文件
with open(file_name, 'rb') as current_file:
# 读取当前文件的数据
data = current_file.read()
# 将当前文件的数据写入到新文件中
f.write(data)
结果可以看到a13应该是第一块IDAT
修改脚本
# 指定要拼接的文件列表
file_names = ['head',
'a13',
'x',
'tail']
# 创建一个新的文件来保存拼接后的数据
for i in range(0, 46):
with open('.//output//'+str(i)+'.png', 'wb') as f:
file_names[-2] = "a"+str(i)
# 遍历所有文件
for file_name in file_names:
# 打开当前文件
with open(file_name, 'rb') as current_file:
# 读取当前文件的数据
data = current_file.read()
# 将当前文件的数据写入到新文件中
f.write(data)
我们再来爆破第二块IDAT
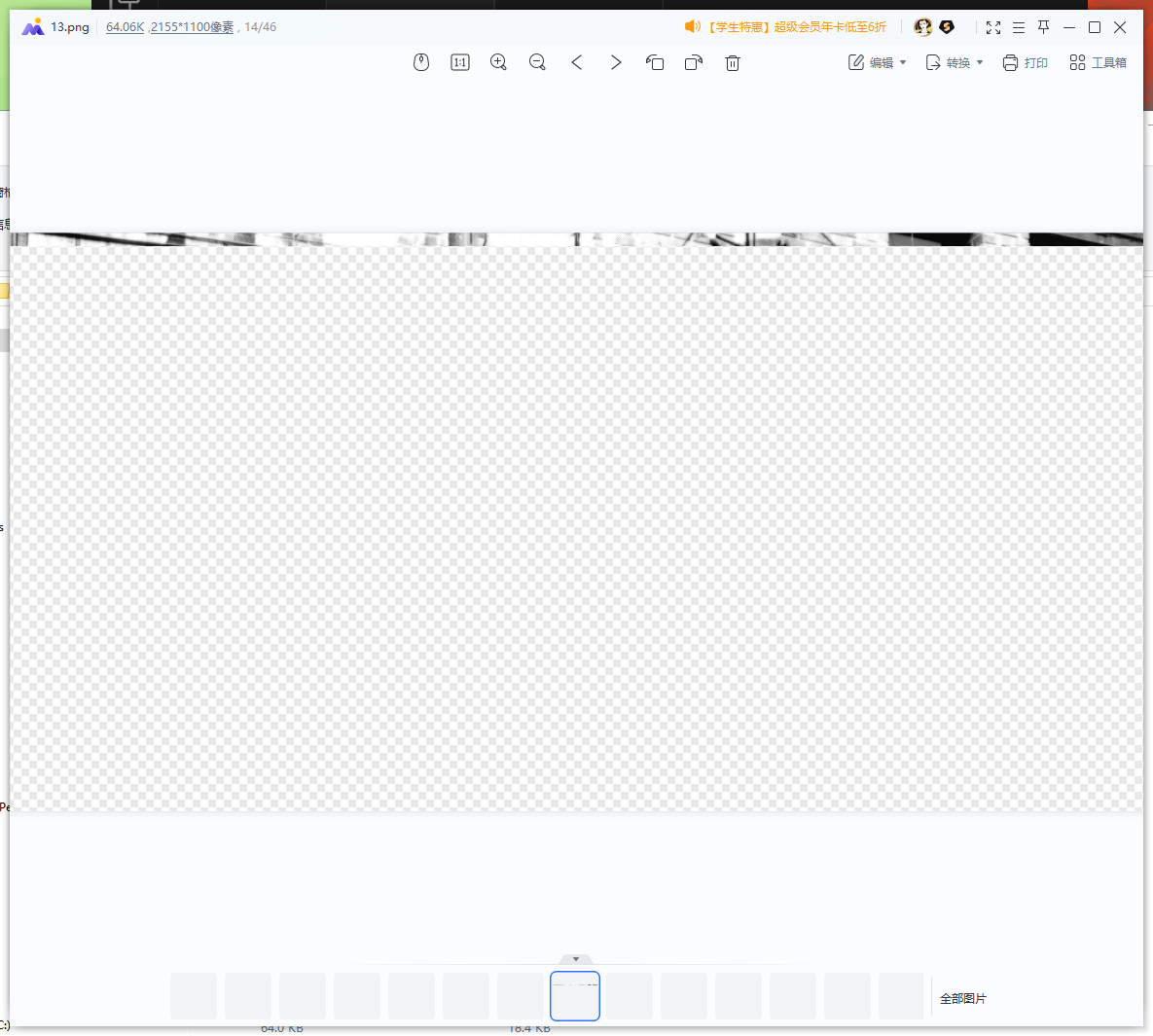
不正确的IDAT块不能正确显示像这样

正确的是这样 所以第二块IDAT是a4

以此类推
最后的脚本是
# 指定要拼接的文件列表
file_names = ['head',
'a11', 'a2', 'a15', 'a41', 'a27',
'a28', 'a40', 'a5', 'a8', 'a10',
'a12', 'a44', 'a9', 'a25', 'a36',
'a38', 'a4', 'a42', 'a7', 'a3',
'a33', 'a19', 'a34', 'a17', 'a14',
'a43', 'a32', 'a13', 'a22', 'a21',
'a18', 'a37', 'a30', 'a29', 'a24',
'a39', 'a31', 'a23', 'a1', 'a16',
'a35', 'a0', 'a20', 'a6', 'a26',
'x',
'tail']
# 创建一个新的文件来保存拼接后的数据
for i in range(0, 46):
with open('.//output//'+str(i)+'.png', 'wb') as f:
file_names[-2] = "a"+str(i)
# 遍历所有文件
for file_name in file_names:
# 打开当前文件
with open(file_name, 'rb') as current_file:
# 读取当前文件的数据
data = current_file.read()
# 将当前文件的数据写入到新文件中
f.write(data)
结果是

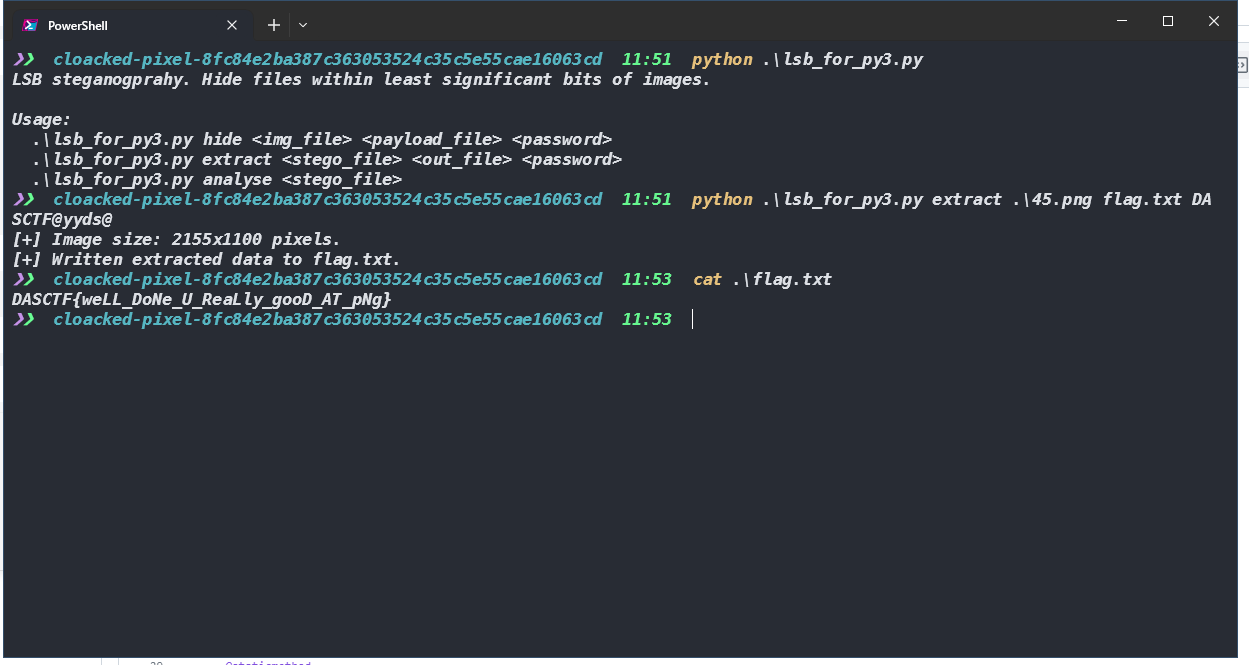
根据提示 密码是DASCTF@yyds@
脚本一把梭
https://github.com/livz/cloacked-pixel
这里我们用py3版本的
https://github.com/livz/cloacked-pixel/blob/8fc84e2ba387c363053524c35c5e55cae16063cd/crypt_for_py3.py
搞定